
Ai curioso: algoritmos alimentados com motivação intrínseca.
O que significa IA orientada por curiosidade? A pesquisa e a inovação na IA nos acostumavam com a novidade e os avanços praticamente lançados diariamente. Agora estamos quase acostumados a algoritmos que podem reconhecer cenas e ambientes em tempo real e se movem de acordo, quem pode entender a linguagem natural (NLP), aprenda trabalho manual diretamente da observação“Invente” vídeo com personagens conhecidos reconstruindo sincronizado imita para áudio, para imite a voz humana até mesmo em diálogos não triviais, e até Desenvolva novos algoritmos de IA sozinhos(!).
As pessoas falam demais. Os seres humanos não são descendentes de macacos. Eles vêm de papagaios. (A sombra do vento – Carlos Ruiz Zafón)
Tudo muito bonito e impressionante (ou perturbador, dependendo do ponto de vista). No entanto, havia algo que ainda estava faltando: afinal, mesmo com a capacidade de se auto-melhorar para obter resultados comparáveis ou até superiores aos dos seres humanos, todas essas performances sempre começaram a partir de informações humanas. Ou seja, são sempre os humanos que decidem tentar a mão em uma determinada tarefa, preparar os algoritmos e “empurrar” a IA em direção a uma determinada direção. Afinal, mesmo os carros totalmente autônomos sempre precisam receber um destino para chegar. Em outras palavras, não importa o quão perfeita ou autônoma seja a execução: a motivação ainda é substancialmente humana.
Não importa o quão perfeita ou autônoma seja a execução: a motivação ainda é substancialmente humana.
O que é “motivação”? Do ponto de vista psicológico, é a “primavera” que nos leva a um certo comportamento. Sem entrar na miríade de teorias psicológicas a esse respeito (o artigo por Ryan e Deci pode ser um bom ponto de partida para aqueles interessados em analisá -lo, além do Entrada da Wikipedia), podemos distinguir genericamente entre motivação extrínsecaonde o indivíduo é motivado por recompensas externas e Motivação intrínsecaonde o impulso para agir deriva de formas de gratificação interior.
:max_bytes(150000):strip_icc()/2795384-differences-between-extrinsic-and-intrinsic-motivation-5ae76997c5542e0039088559.png)
Essas “recompensas” ou gratificações são chamadas convencionalmente ” reforços “, Que pode ser positivo (recompensa) ou negativo (punições) e são um mecanismo poderoso de aprendizado, por isso não é surpreendente que também tenha sido explorado no aprendizado de máquina,
Aprendizagem de reforço
DeepMind’s ALPHAGO foi o exemplo mais incrível dos resultados que podem ser alcançados com o aprendizado de reforço, e mesmo antes que o próprio DeepMind tenha apresentado resultados surpreendentes com um algoritmo que aprendi a jogar videogame sozinho (O algoritmo não sabia quase nada das regras e do ambiente do jogo).
https://www.youtube.com/watch?v=tmpftpjtdgg
No entanto, esse tipo de algoritmo exigia uma forma imediata de reforço para a aprendizagem: [right attempt] – [reward] – [more likely to repeat it] – [wrong attempt] – [punishment] – [less chance of falling back]. A máquina recebe feedback sobre o resultado (por exemplo, a pontuação) instantaneamente, por isso é capaz de elaborar estratégias que levam à otimização para a maior quantidade de “recompensas” possíveis. Essa situação, em certo sentido, se assemelha ao problema com os incentivos corporativos: eles são muito eficazes, mas nem sempre na direção que seria esperada (por exemplo, a tentativa de fornecer aos programadores incentivos por linhas de código, o que se mostrou muito eficaz para incentivar a duração do código, em vez da qualidade, que era a intenção).

No entanto, no mundo real, os reforços externos são frequentemente raros ou mesmo ausentes e, nesses casos, a curiosidade pode funcionar como um reforço intrínseco (motivação interna) para desencadear uma exploração do ambiente e aprender habilidades que podem ser úteis mais tarde.
No ano passado, um grupo de pesquisadores da Universidade de Berkeley publicou um papel notável, provavelmente destinado a avançar os limites do aprendizado de máquina, cujo título era Exploração orientada por curiosidade por previsão auto-supervisionada. A curiosidade nesse contexto foi definida como “o erro na capacidade de um agente de prever a conseqüência de suas próprias ações em um espaço de recurso visual aprendido por um modelo de dinâmica inversa auto-supervisionada”. Em outras palavras, o agente cria um modelo do ambiente que ele está explorando, e o erro nas previsões (a diferença entre modelo e realidade) consistiria no reforço intrínseco, incentivando a curiosidade da exploração.
A pesquisa envolveu três configurações diferentes:
- “Recompensa extrínseca esparsa”, ou reforços extrínsecos fornecidos com baixa frequência.
- Exploração sem reforços extrínsecos.
- Generalização de cenários inexplorados (por exemplo, novos níveis do jogo), onde o conhecimento obtido com a experiência anterior facilita uma exploração mais rápida que não começa do zero.
https://www.youtube.com/watch?v=j3fhoyhun3a
Como você pode ver no vídeo acima, o agente com curiosidade intrínseca é capaz de completar o nível 1 de Supermario Bros e Vizdoom Sem problemas, enquanto aquele sem ele geralmente tende a colidir com as paredes ou ficar preso em algum canto.
Módulo de Curiosidade Intrínseca (ICM)
O que os autores propõem é o módulo de curiosidade intrínseca (ICM), que usa a metodologia de gradientes assíncronos A3C Proposto por Minh et al. por determinar as políticas a serem adotadas.
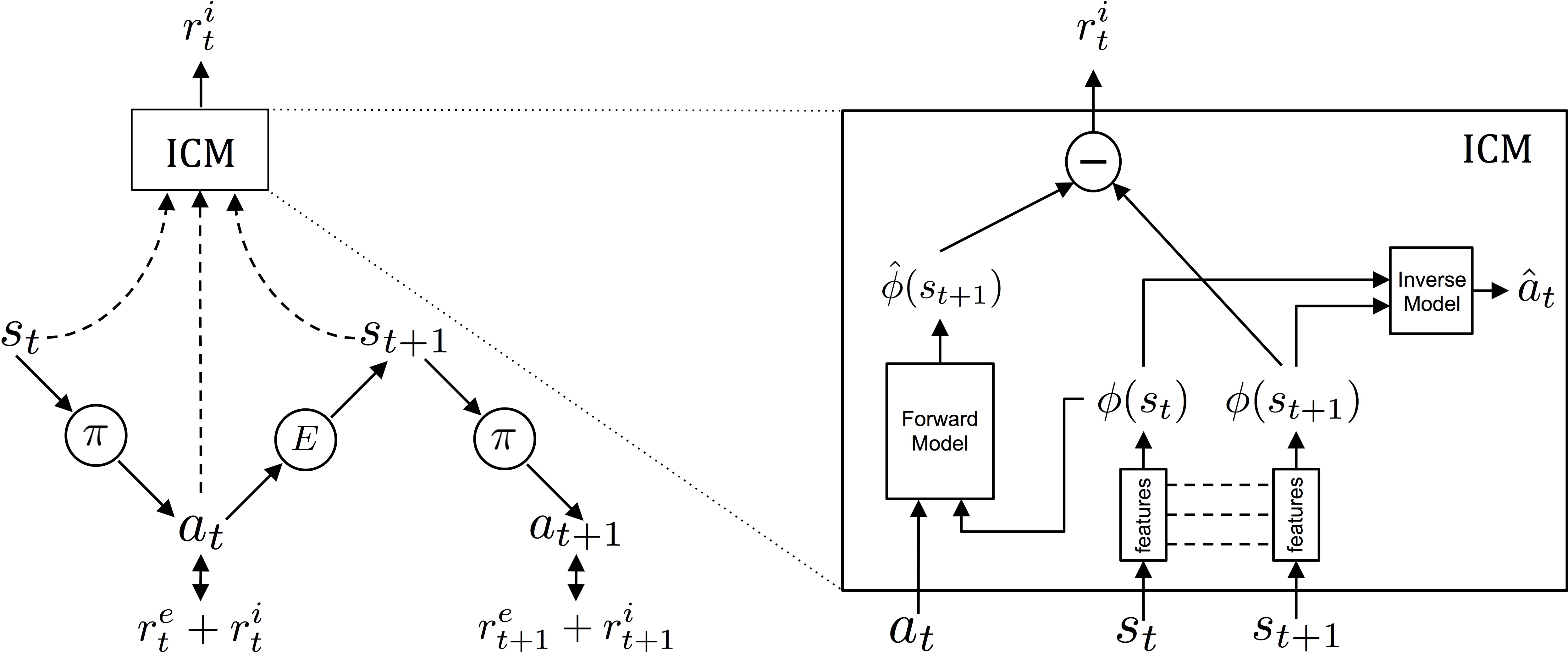
Aqui acima, apresentei o diagrama conceitual do módulo: à esquerda, mostra como o agente interage com o ambiente em relação à política e aos reforços que recebe. O agente está em um determinado estado ste executa a ação αT De acordo com o plano π. A ação αT acabará recebendo reforços intrínsecos e extrínsecos (ret+reut) e modificará o ambiente E levando a um novo estado sT+1… e assim por diante.
À direita, há uma seção transversal de ICM: um primeiro módulo converte os estados brutos st do agente em características φ (st) que pode ser usado no processamento. Posteriormente, o módulo de dinâmica inversa (modelo inverso) usa as características de dois estados adjacentes φ (st) e φ (sT+1) para Preveja a ação que o agente realizou para mudar de um estado para outro.
Ao mesmo tempo, outro subsistema (modelo avançado) também é treinado, que prevê o próximo recurso a partir da última ação do agente. Os dois sistemas são otimizados juntos, o que significa que o modelo inverso aprende recursos relevantes apenas para as previsões do agente, e o modelo avançado aprende a fazer previsões sobre esses recursos.
E daí?
O ponto principal é que, como não há reforços para recursos ambientais que são inconseqüentes às ações do agente, a estratégia aprendida é robusta a aspectos ambientais incontroláveis (veja o exemplo com ruído branco no vídeo).
Para entender melhor um ao outro, o reforço real do agente aqui é a curiosidade, ou seja, o erro na previsão de estímulos ambientais: quanto maior a variabilidade, mais erros o agente cometerá na previsão do ambiente, maior o reforço intrínseco, mantendo o agente “curioso”.

A razão para a extração dos recursos mencionados acima é que fazer previsões baseadas em pixels não é apenas muito difícil, mas torna o agente muito frágil para ruído ou elementos que não são muito relevantes. Apenas para dar um exemplo, se, durante uma exploração, o agente ficaria na frente das árvores com folhas soprando ao vento, o agente corre o risco de fixar as folhas pela única razão pela qual eles são difíceis de prever, negligenciando todo o resto. Em vez disso, o ICM nos fornece recursos extraídos autonomamente do sistema (basicamente de uma maneira auto-supervisionada), resultando na robustez que estávamos mencionando.
Generalização
O modelo proposto pelos autores faz uma contribuição significativa para a pesquisa sobre a exploração orientada à curiosidade, como usando recursos auto-extraídos em vez de prever pixels, tornam o sistema quase imune a ruído e elementos irrelevantes, evitando entrar em becos cegos.

No entanto, isso não é tudo: esse sistema, de fato, capaz de usar o conhecimento adquirido durante a exploração para melhorar o desempenho. Na figura acima, o agente consegue completar o nível 2 do Supermario Bros muito mais rápido, graças à exploração “curiosa” realizada no nível 1, enquanto em Vizdoom ele conseguiu andar no labirinto muito rapidamente sem colidir com as paredes.
Em Supermario, o agente é capaz de completar 30% do mapa sem qualquer tipo de reforço extrínseco. A razão, no entanto, é que, com 38%, há um abismo que só pode ser superado por uma combinação bem definida de 15 a 20 chaves: o agente cai e morre sem qualquer tipo de informação sobre a existência de outras partes do ambiente explorável. O problema não está por si só conectado ao aprendizado por curiosidade, mas é certamente um obstáculo que precisa ser resolvido.
Notas
A política de aprendizado, que neste caso é o Crítico de ator de vantagem assíncrona (A3C) Modelo de Minh et al. O subsistema de políticas é treinado para maximizar os reforços ret+reut (onde ret está perto de zero).
Links
Richard M. Ryan, Edward L. Deci: Motivações intrínsecas e extrínsecas: definições clássicas e novas direções. Psicologia Educacional Contemporânea 25, 54–67 (2000), doi: 10.1006/cps.1999.1020.
Em busca dos fundamentos evolutivos da motivação humana
D. Pathak et al. Exploração orientada a curiosidade por previsão auto-supervisionada. ARXIV 1705.05363
Máquinas inteligentes aprendem a ser curiosas (e jogar Super Mario Bros.)
Im de Abril, R. Kanai: Aprendizagem de reforço orientado a curiosidade com regulamentação homeostática – Arxiv 1801.07440
Os pesquisadores criaram uma IA que é naturalmente curiosa
V. Mnih et al.: Métodos assíncronos para aprendizado de reforço profundo – ARXIV: 1602.01783
Crítico de ator de vantagem assíncrona (A3C) – Github (código -fonte)
Métodos assíncronos para aprendizado de reforço profundo – O papel da manhã
Os 3 truques que fizeram do Alphago zero funcionar
Andrea trabalha nele há quase 20 anos, cobrindo sobre tudo, do desenvolvimento à análise de negócios, ao gerenciamento de projetos.
Hoje podemos dizer que ele é um gnomo despreocupado, apaixonado por neurociências, inteligência artificial e fotografia






{kind=link}