
Dados dentro do DNA, ou o mundo dentro de uma caixa de sapatos
Em 2016, um post assinado por Thomas Barnet Jr. intitulado “A era Zettabyte começa oficialmente”Apareceu no blog da Cisco. O que é tudo?
O post estava se referindo ao tráfego global da Internet, conforme medido pela Cisco, que em 2016 acabara de exceder o ZB1e esperado Para exceder o 3 ZB até 2021. Mas o tráfego ainda não é nada comparado aos dados gerados (que excederam o ZB já em 2012), enquanto o IDC, em seu relatório Dados Idade 2025 mostrou que o limiar de 20 ZB já foi excedido este ano e que esse crescimento exponencial levaria a quebrar o 160 ZB até 2025!

Um dilúvio de dados
Estamos gerando uma quantidade imensa de dados e somos rapidamente chegando ao capacidade limite da tecnologia atual para lidar com isso. Alguns podem argumentar que grande parte dos dados gerados é um lixo que pode ser facilmente excluído sem nenhum problema, mas é difícil entender hoje o que pode se tornar relevante no futuro, portanto isso certamente não pode ser considerado uma solução.
O Big Data já é um desafio em termos de capacidade de computação hoje, mas em breve se tornará um desafio em termos de espaço com as tecnologias de hoje: SSD A mídia trouxe alguma melhoria de desempenho em relação aos discos rígidos magnéticos, mas com que preocupações de armazenamento a longo prazo ainda estamos presos a fitas magnéticas.
Genética para o resgate?
Em 2007, a GM Skinner, K. Visscher e M. Mansuripur publicaram um artigo bastante revolucionário no Journal of Bionanocience, intitulado Escrita biocompatível de dados no DNAonde eles usaram um esquema de armazenamento simples baseado em DNA. Neste trabalho, o grupo demonstrou a possibilidade de “escrever” informações em fios de DNA e lê -lo usando um gel específico. O método ainda era rudimentar, mas o caminho foi pavimentado.

Sequenciamento e síntese
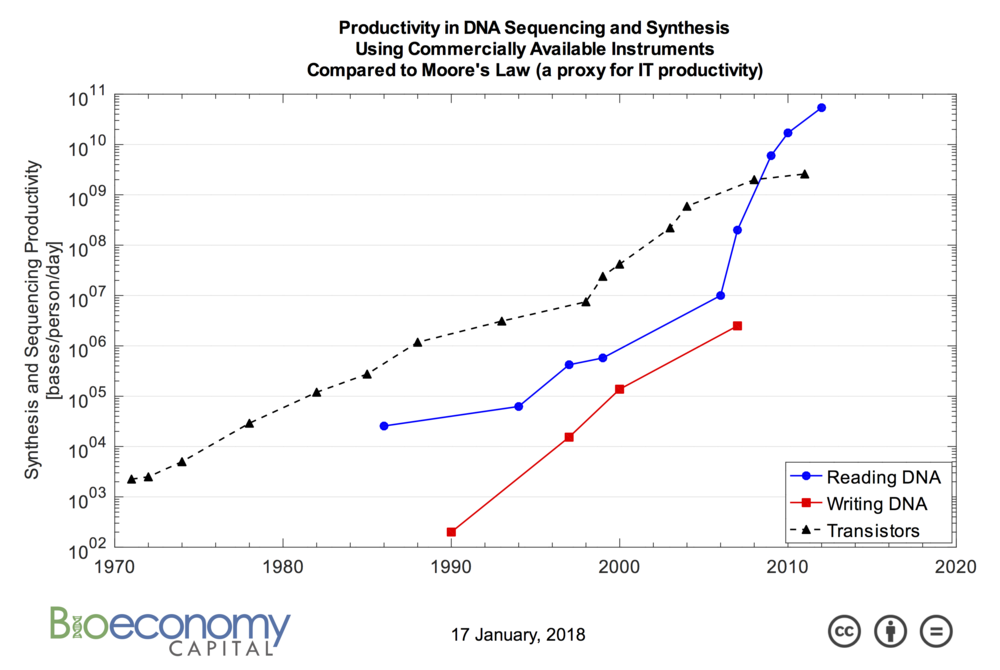
O processo de leitura de DNA, mais conhecido como “sequenciamento”, recebeu um grande impulso do trabalho do NHGRI dentro do escopo do Projeto do genoma humanoque foi concluído em 2003.

O DNA é feito de 4 bases: UMnegar, Guanine, THimina e citosina. O “truque” é que as únicas combinações permitidas são entre adenina e timina, e entre citosina e
Por que DNA?
Existem muitas vantagens:
- Densidade: O DNA é acima de tudo incrivelmente denso. Já ano passado O limiar de 200 petabytes (1000 TB) por grama foi excedido. Estima -se que todos os dados na Internet hoje possam estar facilmente contidos no DNA no espaço de uma caixa de sapatos (!).
- Lealdade: A recuperação de dados pode ser praticamente livre de erros devido à precisão dos métodos de replicação de DNA.
- Sustentabilidade: A energia necessária para manter as informações codificadas pelo DNA é uma pequena fração da exigida pelos data centers modernos.
- Longevidade: O DNA é uma molécula estável que pode durar milhares de anos sem degradação.
O Sequenciamento As tecnologias agora estão muito avançadas e hoje existem até sequenciadores de bolso USB (veja abaixo), e os dispositivos mais avançados permitem a execução de muitas corridas em paralelo.

A escrita (ou síntese) do DNA requer “anexar” uma base após a outra em um ambiente controlado, um processo químico muito lento que remonta a 1981. No entanto, dada a enorme demanda do mercado, existem empresas como Twist Bioscience e Script de DNA que desenvolveram tecnologias inovadoras de síntese, baseadas respectivamente na síntese de silício e enzimática, que prometem volumes de magnitude maiores que as tradicionais. Além disso, apenas recentemente, dois pesquisadores no Informática de Biologia Sintética Departamento de JBei apresentado uma nova metodologia de síntese que poderia levar ao criação de impressoras 3D de DNA.
Desde o trabalho da Skinner & Coll. A pesquisa fez um grande progresso: em 2015, Microsoft e Misl da Universidade de Washington criou o Armazenamento de DNA Projeto, estabelecendo um recorde em 2016 armazenando e recuperando com sucesso 200 MB em fios de DNA. Em 2017, em outro trabalho importanteY. Erlich e D. Zielinski, armazenados e recuperados 2 MB de material com uma densidade de mais de 200 petabyte por grama, tocando o limite teórico Postulado por Shannonatravés do uso de “códigos da fonte”.

Até hoje, o processo de síntese/seqüenciamento de DNA ainda é caro (estamos falando de alguns milhares de dólares por MB por escrito e 200 para leitura), mas isso deve cair, tanto em vista da rápida evolução do setor, devido à solicitação explosiva do DNA de engenharia, porque o armazenamento dos dados é possível usar o Synthesized DNA em vez de sintetizado em vez de BI. A este respeito, é esperado que o uso extensivo de tecnologias de edição, como CRISPR/CAS9Assim, Talen
Aplicações
O uso do DNA para digitalização não é, portanto, algo que pertence à ficção científica, mas já estamos começando a ver os primeiros protótipos de aplicações.
- Criptografia:
Carverr uma startup americana desenvolveu um método para criptografar dados em moléculas de DNA e oferece um Serviço de criptografia de senha baseada em DNA por US $ 1.000. - Nuvem: apenas em março passado, a Microsoft publicou um papel na natureza, onde demonstrou a capacidade de realizar leituras de DNA através
aleatório Acesso, aumentando drasticamente a eficiência do processo de sequenciamento. Graças ao progresso como este e aos mencionados acima, a Microsoft parece estar começando a considerar DNA para backup em nuvem para o futuro e está colaborando ativamente com Twist Biosciences. Os custos ainda são muito altos, mas as pessoas em Redmond estão convencidas de que esse obstáculo será facilmente superado se houver demanda suficiente da indústria de computadores.
Observação
Um Zettabyte é equivalente a cerca de um bilhão de terabytes (TB). Se considerarmos que 1 TB é mais ou menos o tamanho de um disco rígido médio hoje, é fácil perceber o tamanho desse tráfego.
UM Código da fonte é uma maneira de obter dados (por exemplo, um arquivo) e transformá -los em um número realmente ilimitado de pedaços codificados, para que o arquivo original possa ser remontado por qualquer conjunto dessas peças, desde que o total seja um pouco maior que o tamanho original. O que torna esse tipo de algoritmo notável é que ele permite enviar informações através de canais “barulhentos” sem exigir que o receptor envie feedback sobre pacotes ausentes. Em outras palavras, ter um arquivo de 10 MB, pois o destinatário será suficiente para
Com Acesso aleatório Nele, queremos dizer a capacidade de acessar qualquer local da mídia sem precisar passar pelos locais anteriores (acesso serial).
Links
Uma linha do tempo interativa do genoma humano
Wikipedia: armazenamento digital de DNA
Armazenar
A ascensão do armazenamento de dados de DNA
Acesso aleatório em armazenamento de dados de DNA em larga escala
Armazenamento de dados de DNA mais próximo de se tornar realidade
Como o DNA poderia armazenar todos os dados do mundo
O armazenamento de dados no DNA traz a natureza ao universo digital
Rumo ao armazenamento prático de baixa manutenção de informações digitais em DNA sintetizado (PDF)
Armazenamento de DNA: um novo método para armazenar informações digitais
O DNA sintético empurrará o Ledger e o Trezor do mercado?
Síntese e sequenciamento
Extração de DNA com uma centrífuga impressa em 3D
Engenharia reversa Um sequenciador de DNA
Nova pesquisa pode levar à impressora 3D de DNA
A fonte de DNA permite uma arquitetura de armazenamento robusta e eficiente (PDF)
Minion: um sequenciador de DNA completo em um bastão USB
Aplicações
Os fanáticos por bitcoin estão armazenando suas senhas de criptomoeda no DNA
A impressão 3D pode ser a chave para armazenamento de dados acessível usando DNA
Algoritmos muito legais: códigos de fonte
Andrea trabalha nele há quase 20 anos, cobrindo sobre tudo, do desenvolvimento à análise de negócios, ao gerenciamento de projetos.
Hoje podemos dizer que ele é um gnomo despreocupado, apaixonado por neurociências, inteligência artificial e fotografia





